How AI is Changing the SaaS Paradigm
AI is transforming the SaaS industry through synthetic joins on the fly, thereby enhancing data manipulation and insight generation to a level that was beyond imagination.
What if your SaaS could think beyond its data? You're about to discover how AI is transforming the way how modern software companies handle information.
We want to let you in on something that’s a little more complex than what you’d get from your average AI influencer on LinkedIn. Lock the toilet door – the next 5 minutes will be fun.
#To simpler times: How the (current) SaaS model made billions
Every SaaS company is essentially a wrapper around a database. The functions you use – create, read, update, delete – are all about manipulating data stored in that database.
For example, running a SQL query like:
SELECT name FROM customers_table WHERE last_month_revenue = 1800;
retrieves names of customers who brought in over $1,000 last month.
A bit closer to reality, we might join information from two tables – customers and revenues:
SELECT customers.name, revenues.last_month_revenue FROM customers JOIN revenues ON customers.id = revenues.customer_id WHERE revenues.last_month_revenue = 1800;
You can visualize the logic like this:
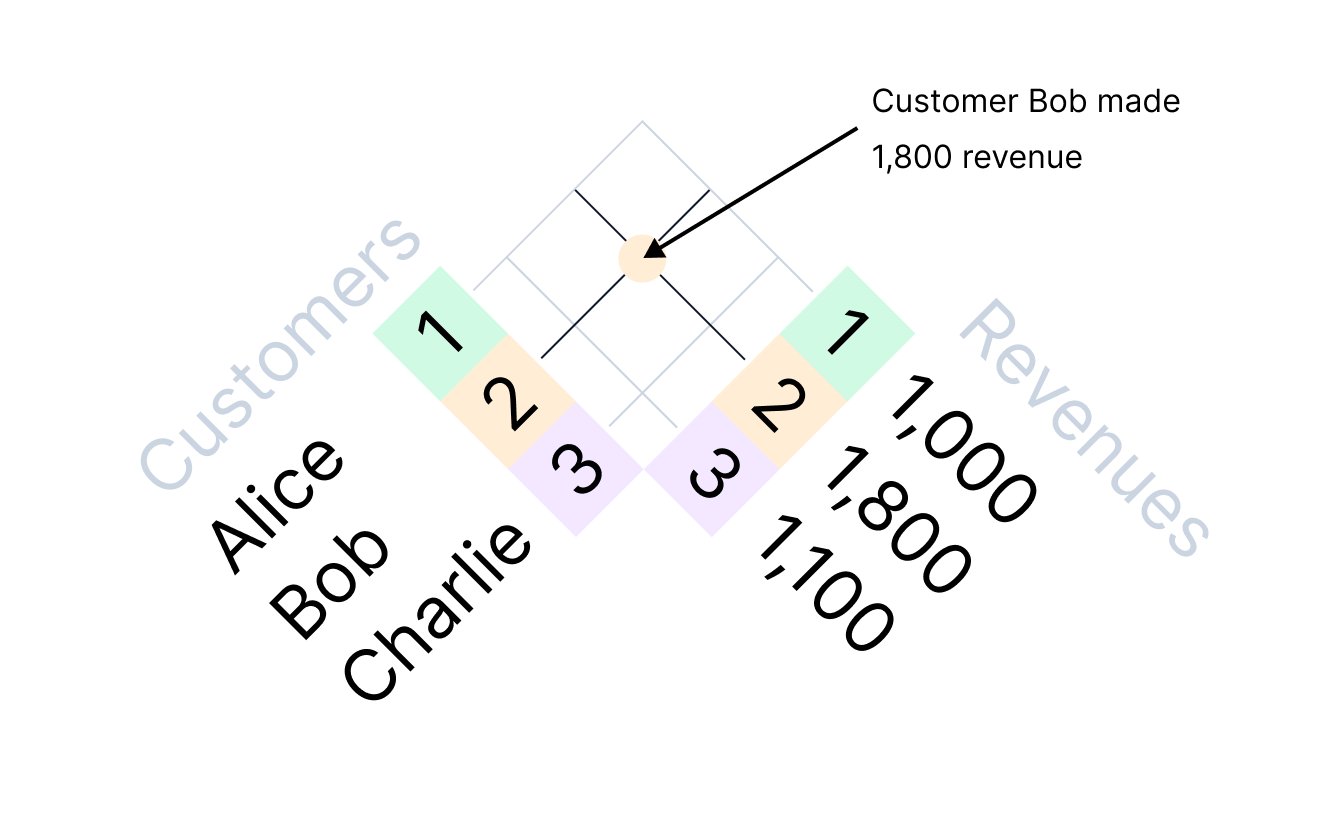
But what happens when we move beyond structured data?
#The new SaaS paradigm: Generating insights beyond data
Language models are changing the SaaS landscape by generating new, actionable information from both structured and unstructured data – instantly. Just as a project status update can be turned into a sonnet, data can be transformed into something more useful for your needs.
This shift brings data closer to what we consider “information”: abstract knowledge that provides a competitive edge. While language models aren’t new, their current accuracy and vast world knowledge are unprecedented.
For example, you want to know who of your customers is going to any of the conferences you bought an expensive booth for. What you probably want is something like this:

This newly generated data can be connected to existing data, creating connections that previously seemed impossible. This capability is akin to using =INDEX(MATCH) instead of =VLOOKUP in Excel, but on a much larger scale – connecting information that doesn’t exist in either of the two original data sources.
#Old wine in new bottles?
You might wonder, “Couldn’t I just insert new information into another table and achieve the same result?” In theory, yes. But practically, setting up a flexible database that can generate and connect data on the fly is complex.
As if getting a list of conference attendees wasn’t hard enough already, there also has to be an identifier for such joins to work.
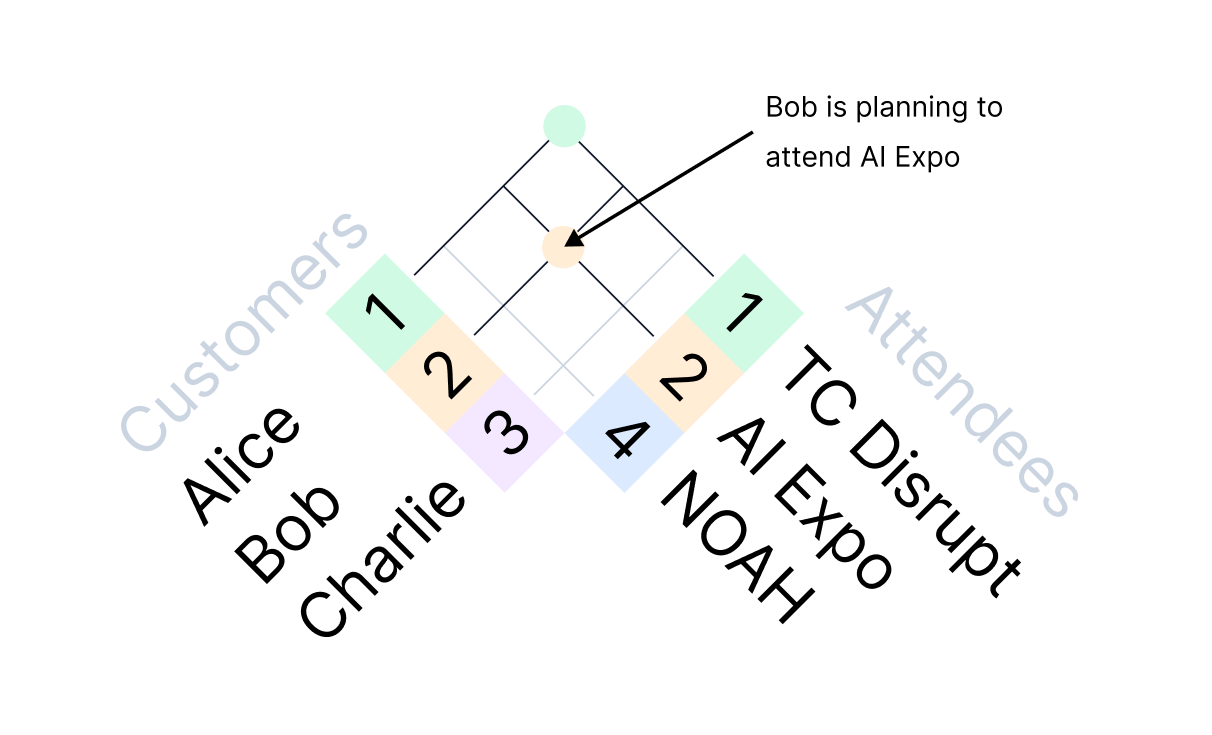
If you aren’t collecting this information at scale, setting up a separate table for such cases may be overkill. You just want to do something with the information once and move on.
Today, data can be generated at the push of a button, making the mere possession of data less valuable. The real value lies in creating models and links that derive meaningful insights from this data.
#Data quality as first-class citizen
The power of these new AI capabilities still depends on the quality of input data. If someone logs a note in the CRM saying, “Michelle hates our product,” the AI won’t ignore it, even if it’s not true. This highlights the importance of reliable data.
Manual data processing is prone to errors, slow, and requires significant management. Contrast that with today’s AI, you can operationalize vast amounts of knowledge with speed and precision.
That said, it’s not enough to simply dump 100K rows of customer data into ChatGPT and expect expert conclusions. For AI to accurately make predictions, it needs context—just as a new employee would require guidance. But unlike an employee, AI doesn’t forget crucial details or take vacations when you urgently need insights.
This doesn’t necessarily mean models require extensive training; they just need enough context to make decisions on the fly. The more flexible the input, the more powerful the AI’s output.
#Conclusion
Incorporating LLMs into your SaaS strategy isn't just an upgrade – it's becoming a necessity. Companies that embrace this new paradigm will excel in a data-driven world.
AI-based products thus have the chance to live up to their decade-long promises: Be the flexible tool that is faster, cheaper, and better than (1) doing something (semi-) manually or (2) not doing something at all.
Just as people expect reliable results without thinking about databases, few want to manually dig for information and match data on identifiers that are yet to be created. But everyone will happily work with reliable results of both. In the end, it’s the results that matter, not the process. What truly matters is the reliability of the results, not the process behind them.
Join the Narratic AI Insider Circle
Get early access to insights, product updates, and discussions on the future of AI for revenue teams
